

マイクロアーキテクチャ解説とコア部分の性能検証
内部命令バッファを拡張
実行ユニットをAVX対応に
Sandy Bridgeのアーキテクチャの最大のテーマは、256bitのベクトル幅を持つ新しい拡張命令AVX(Advanced Vector Extensions)のサポートだ。AVXの概要と効果の検証はこちらで行なっているが、ここではコア内部の改良点について触れていきたい。
まず、命令の取り込み部分にキャッシュが追加された。Pentium Pro以降のx86 CPUは、x86命令をμOPと呼ばれる内部命令に変換(デコード)してからアウトオブオーダー(命令の順序を無視して)で並列実行していく。このデコードはかなり複雑で電力を消費する作業でもある。従来もループ命令を検出してμOPを再利用するLSD(ループストリームディテクター)という回路があったが、Sandy Bridgeでは1,500個と、従来より多くのμOPをキャッシュするとともに本格的な予測ロジックを用意。積極的にデコードをスキップできるようにした。
また、AVXの256bitデータに対応するため、各種内部バッファ類を増強している。なかでも従来リオーダバッファを利用していた演算途中のデータの格納用に、物理レジスタファイルを用意したことも大きい。リオーダバッファとリザベーションステーション(実行待ちのμOPを待機させておくところ)の間で頻繁にデータをコピーするロスを省けるので、効率的で消費電力の低減効果もあるという。リオーダバッファ(位置情報の管理に利用)やリザベーションステーションの命令エントリーを増やすことで、実行ユニットの利用効率も上げている。
| Nehalem | Sandy Bridge | |
|---|---|---|
| ロードバッファ | 48 | 64 |
| ストアバッファ | 32 | 36 |
| リザベーションステーション | 36 | 54 |
| 整数物理レジスタファイル | - | 160 |
| 浮動小数点物理レジスタファイル | - | 144 |
| リオーダバッファ | 128 | 168 |
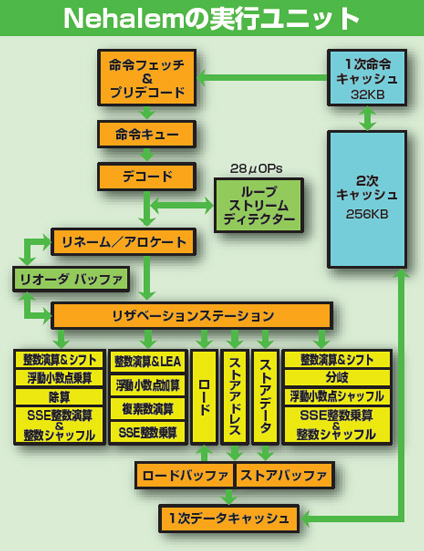
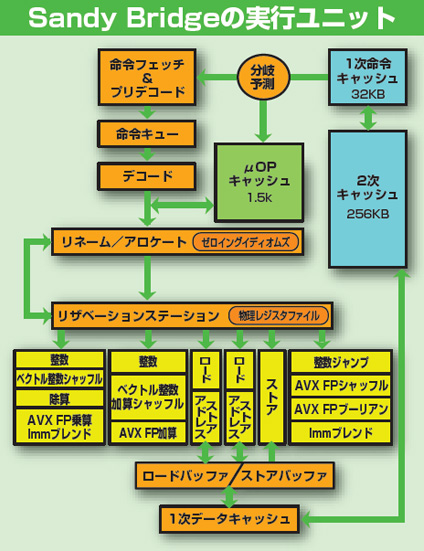
NehalemとSandy Bridgeのコア内部構造の違い。LSDがμOPキャッシュに進化したことと、物理レジスタファイルが用意されたことが大きい。各種実行ユニットは128bit幅のままだが、ベクトル整数用とベクトル浮動小数点用と、同時に利用されることがない回路を適宜どちらかの用途に合わせて使うことで256bit演算を1サイクルで実行できる。また、ロード/ストアアドレスを2ポートに増やし、256bit(128bit×2)での命令ロードやアドレス生成が可能になっている


このように、Sandy Bridgeでの拡張の直接のテーマのほとんどは、256bit幅のAVX対応にあるわけだが、μOPキャッシュや命令バッファの増量は、従来の命令でも効果があるはず。その効果を確認してみたい。
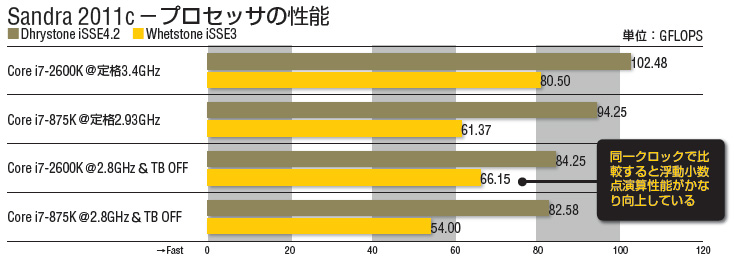
Sandra 2011cにはCPU内部の演算性能を見るために、キャッシュやメモリなどの影響がほとんどない小さなワークセットで動作する演算プログラムが用意されている。これを利用し、新旧Core i7の動作クロックを2.8GHzに揃えて性能を比較したのが上のグラフだ。不確定要素を排除するため、Turbo Boost(TB)をOFFにしたスコアを基本としているが、参考までにそれぞれのCPUのクロックを統一しない定格状態(TBもONのまま)でのスコアも併記した。
「プロセッサの性能」テストでは、整数演算(Dhrystone)は誤差に近いような差しかないが、浮動小数点演算(Whetstone)では約23%と、かなりの向上が確認できた。また、SSEを使って整数と浮動小数点のベクトル演算を行なう「マルチメディア処理」では、整数で約6%、32bit浮動小数点演算で約8%、64bit倍精度浮動小数点演算では約8%の性能向上が確認できた。コア間のデータ交換の帯域が20%アップ、コア間のレイテンシの向上も確認できている。また、同じくクロックを揃えて行なったCINEBENCHR11.5のレンダリングテストでもシングルコアによる処理で約20%の性能向上が確認できた。
まとめ
CPUコア内部の改良部分だけでも
かなりの性能向上につながっている
Sandy Bridgeにおけるコア内部の改良は、256bit幅のAVX命令の効果的な実行をテーマにしたものが中心となっているが、実行ユニットの利用効率を上げてクロックあたりの処理性能を向上させるアプローチも続けられている。Sandra 2011cで確認できたように、128bit幅のSSE命令の実行性能でも浮動小数点演算を中心に確実な改善が見られる。CINEBENCH R11.5での性能向上は必ずしもコア内部の改良だけによるものとは限らないが、コアの演算性能に大きくかかわるテストとして実行した。キャッシュやメモリまわりの改善効果もあるだろうが、同一クロックでTurbo Boostなしという条件でも、シングルスレッド性能で20%もの性能向上というのは、そうとうな処理効率の改善と言える。
【検証環境】
[LGA1155環境]
マザーボード:ASUSTeK P8P67 WS Revolution(Intel P67)
[LGA1156環境]
マザーボード:ASUSTeK P7P55-E EVO(Intel P55)
[共通環境]
メモリ:センチュリーマイクロ CK2GX2-D3U1333(PC3-10600 DDR3 SDRAM 2GB×2)、ビデオカード:EVGA GeForce GTX 460 01G-P3-1371-KR(NVIDIA GeForce GTX 460)、SSD:Micron Technology Crucial RealSSD C300 CTFDDAC256MAG-1G1(Serial ATA 3.0、MLC、256GB)、電源:Corsair Memory CMPSU-850HXJP(850W)、OS:Windows 7 Ultimate 64bit版















