
CPU、GPU両方に効果アリ! キャッシュ・メモリ性能を見る
CPUにGPUコアを集積しつつキャッシュシステムを再構築
Sandy Bridgeの大きな特徴として、同一のダイにCPUコアとGPUコアを集積していることが挙げられる。GPUコアの統合については第1世代Core iシリーズのデュアルコアモデル(Clarkdale)から行なっていたが、あくまでもパッケージレベルでの統合であり、CPUコアは32nm、GPUコアは45nmと別々のプロセスルールで製造したダイをCPUパッケージ内で結合したものだ。
Sandy Bridgeでは同一のダイにCPUコアとGPUコアを集積しているだけでなく、それを前提にして、より効率的なキャッシュ/メモリコントローラの仕組を再構築している点が新しい。その仕組の特徴的な部分が、LLC(Last Level Cache=ラストレベルキャッシュ)とリングバスだ。LLCは、従来CPUコアの3次キャッシュに相当するが、CPUの各コアに隣接する形でCPUコアの数だけ分割(クアッドコアの場合は4ブロックに分割)して実装される。Sandy Bridgeでは、CPUコアだけでなくGPUコアもこのLLCを共有して使えるようにすることでGPUコアのパフォーマンスを向上させるとともに、消費電力の低減も図っている。LLCは、GPUコアから見れば2次キャッシュということになる。
そして、各CPUコアとLLCの各ブロック、GPUコア、システムエージェントを横断的にリング型の高速バスで接続している。この方式は接続するユニット(CPUの場合はコアなど)が増えても配線が集中し過ぎることがなく、シンプルで高速なデータ帯域を得られるメリットがある。キャッシュがコアの分だけ分割されて管理されていることは、コヒーレンシ(各キャッシュ間での内容の同一性)のチェックなど管理の手間が増えることにはなるが、キャッシュヒット/ミスヒット(必要とするデータがキャッシュにあるかどうか)を検知する上では都合がよい。また、データバスがそれぞれ独立していることから、単純に考えれば帯域は最大4倍である。
| 製品名 | アーキテクチャ | 3次 キャッシュ 容量 |
対応メモリ | メモリ帯域 |
|---|---|---|---|---|
| LGA1366版Core i7-980X XE | Nehalem | 12MB | DDR3-1066/3ch | 25.6GB/s |
| LGA1156版Core i7-870 | Nehalem | 8MB | DDR3-1333/2ch | 21.3GB/s |
| LGA1156版Core i7-680 | Nehalem | 4MB | DDR3-1333/2ch | 21.3GB/s |
| LGA1155版Core i7-2600K | Sandy Bridge | 8MB | DDR3-1333/2ch | 21.3GB/s |
| LGA1155版Core i5-2500K | Sandy Bridge | 6MB | DDR3-1333/2ch | 21.3GB/s |
| LGA1155版Core i3-2120 | Sandy Bridge | 3MB | DDR3-1333/2ch | 21.3GB/s |
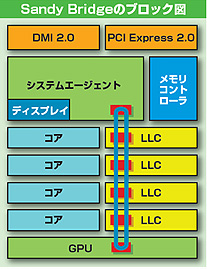
Sandy BridgeはCPUコアとGPUコア、システムエージェント(North Bridge的役割)を1チップに集積。各コア/キャッシュの接続にリングバスを採用することで高速なデータ帯域を実現した
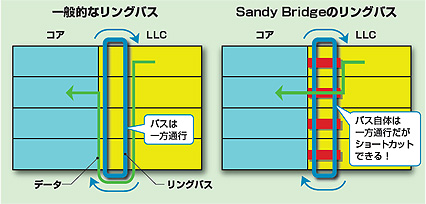
単純に各コアやキャッシュを横断するだけのリングバスだとデータのレイテンシが増大してしまうが、Sandy Bridgeのリングバスではリングストップ(データの出入り口)を各コア/キャッシュにまたがって二つずつ用意することで、ムダを最小限に減らしている
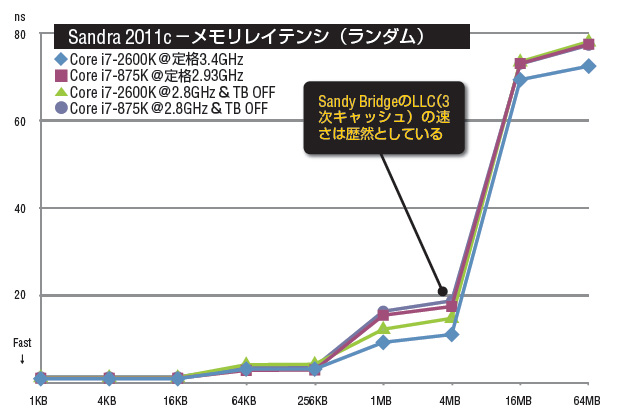
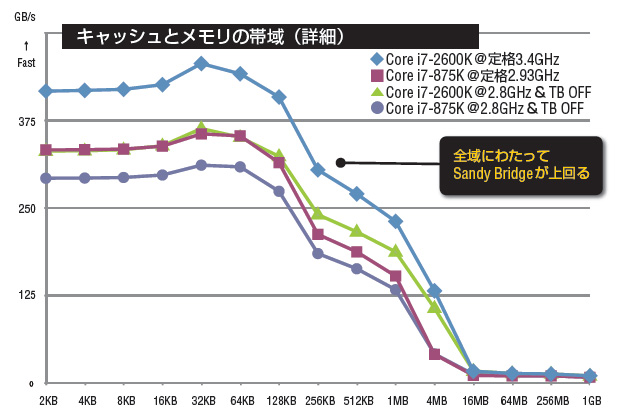
この分割管理とリングバスを経由してのキャッシュ/メインメモリアクセスの効率はこれまでと比べてどうなのかをSandra 2011cのテストで確認してみたい。ここでも新旧のCore i7を使い、純粋なメモリまわりの改良点を見るためにクロックを2.8GHzで統一、Turbo BoostをOFFにしてテストを行なっている。
まずは「メモリレイテンシ」を見てほしい。2次キャッシュのカバー範囲である64~256KBではわずかに旧Core i7のほうがよいが、3次キャッシュのカバー範囲になる4MBでは約3.3nsと新Core i7がかなり大幅なレイテンシ(遅延)の削減ができている。
次は「キャッシュとメモリの帯域(詳細)」を見てみよう。こちらは1次キャッシュのカバー範囲(4コア合計128KBまで)からメインメモリのカバー範囲まで、全域で新Core i7のほうが上だ。ここでも3次キャッシュのカバー範囲の4MBの部分で差が大きくなっている。
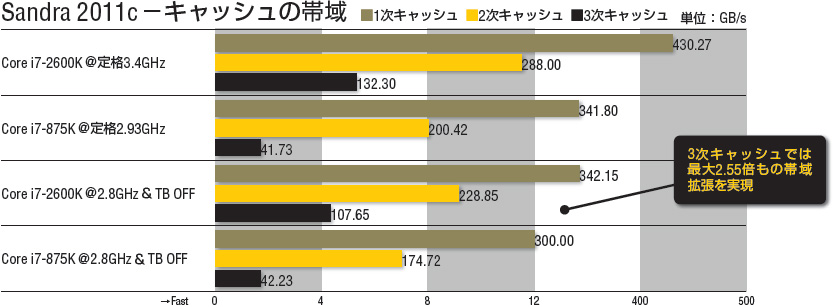
「キャッシュの帯域」のグラフはこの詳細グラフから各キャッシュのカバー範囲の部分を抜き出したものである。同一クロックの比較において、新Core i7は1次キャッシュで約1.14倍、2次キャッシュで約1.31倍、3次キャッシュでは何と約2.55倍もの帯域拡張を実現している。これは非常に大きい。
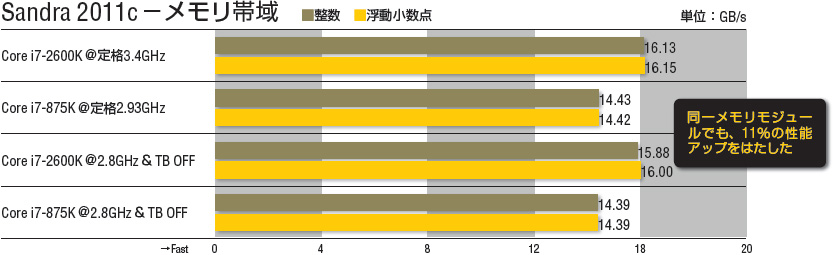
最後に「メモリ帯域」だ。使用メモリモジュールは設定含めてまったく同一であるが、2.8GHz統一時で新Core i7のほうが約11%の性能アップを見せている。これは文字どおりメインメモリ帯域を計測するテストではあるが、レイテンシやキャッシュ帯域も含めてメインメモリアクセスの総合力を反映する傾向があるので、おそらくメモリコントローラ自体の効率が上がったと言うよりは、これまで見てきた各種キャッシュの高速化が影響していると思われる。
まとめ
スプリットLLCとリングバスを採用した
キャッシュは実に強力である
Sandy Bridgeコアで再構築されたキャッシュ/メモリシステムは実に強力だ。1次キャッシュ/2次キャッシュの帯域が大幅に改善されている上、リングバスで接続されたスプリット3次キャッシュ(LLC)のパフォーマンスはまさに爆速。あえて同クロックに統一して比較したが、実際には新Core i7は旧Core i7より大きく動作クロックが向上している。キャッシュはCPUクロックに同期して動作するため、性能差はもっと大きい。実際、Core i7-2600KとCore i7-875Kを定格動作時で比べると、3次キャッシュの帯域では約3.2倍も向上している。キャッシュを大容量化するとレイテンシが大きくなるという課題を見事にクリアしている。これはシステム全体の性能向上にも大きく貢献すると思われる。
【検証環境】
[LGA1155環境]
マザーボード:ASUSTeK P8P67 WS Revolution(Intel P67)
[LGA1156環境]
マザーボード:ASUSTeK P7P55-E EVO(Intel P55)
[共通環境]
メモリ:センチュリーマイクロ CK2GX2-D3U1333(PC3-10600 DDR3 SDRAM 2GB×2)、ビデオカード:EVGA GeForce GTX 460 01G-P3-1371-KR(NVIDIA GeForce GTX 460)、SSD:Micron Technology Crucial RealSSD C300 CTFDDAC256MAG-1G1(Serial ATA 3.0、MLC、256GB)、電源:Corsair Memory CMPSU-850HXJP(850W)、OS:Windows 7 Ultimate 64bit版















