| その他の特集(2011年) | |||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|||
|
|
||||||||||||||
 |
||||||||||||||
|
||||||||||||||
| TEXT:鈴木雅暢 | ||||||||||||||
|
||||||||||||||
|
||||||||||||||
| Core i7に関しては、メモリコントローラなどCPUコア周辺やHyper-Threadingのサポートなどの話題が先行し、コア内部の改良点が話題に上ることは少ない。実際、Core i7世代のマイクロアーキテクチャはCore 2シリーズ世代の「Core Micro-architecture(MA)」のマイナーチェンジ扱いとなっており、新しい名称も用意されず、Intelの文書でも「Core MA(Nehalem)」と表記されているだけ。それでもCore i7世代では興味深い変更がいくつか行なわれている。 Core 2世代とCore i7世代の命令とデータの流れを示すブロック図を下に示す。どちらも基本的な流れには変更がなく、取り込んだx86命令を四つのデコーダでデコードして内部命令(μOPs)に変換し、アウトオブオーダー(命令の順番を守らずに)で並列実行する。 Core i7世代での主な変更点は別掲のとおりだが、興味深いのは「ループストリームディテクター(LSD)」の配置転換だ。LSDは何度も繰り返し実行される命令を見付けて保持するバッファだが、Core MAではこのLSDが命令フェッチの前に置かれ、18個のx86命令を保持していた。Core MA(Nehalem)ではこのLSDがデコーダの後に移動し、デコード後の内部命令を28μOPs保持するように変更された。つまり、これがうまく機能した場合、分岐予測、フェッチに加えてデコードの手間も省けるので、より高い性能向上と電力削減効果が得られる。 また、デコード時に特定のx86命令をペアにして一つのx86命令として扱うことでデコード能力をアップする「Macro- Fusion」が64bitコードにも対応した。分岐予測も強化し、2次の分岐予測器を追加したマルチレベルの分岐予測システムを導入している。予測が外れるということは処理された命令がムダになるということであり、その外れの確率が減るということは、性能向上、電力削減両方に大きな効果がある。 さて、デコードされた命令は、スケジューラによってリザベーションステーション(命令の待合室)を経由し、データが揃ったタイミングで実行エンジンに投入(発行)される。この流れもCore MAから変わっていないが、命令発行ポートはCore MAの5からCore MA(Nehalem)では6ポートに増え、1サイクルで最大六つのμOPsの同時実行が可能となっている。演算ユニット自体は三つで従来と変わらないが、ストアユニットが二つに分かれている。さらにリオーダバッファの拡張により、スケジューリングできるμOPsは従来の96個から33%増えて128個となった。また、仮想アドレスと物理アドレスの変換情報を保持しておくTLB(Translation Lookaside Buffer)についても構造の見直しが行なわれ、データ1次TLBの大幅サイズアップ、2次TLBをデータ/命令兼用とし、512エントリーに増やすなどの拡張が行なわれた。 また、Core i7では、「SSE4.2」という七つの新しい拡張命令をサポートしている。このSSE4.2には、SSE演算用の128bitレジスタ(XMMレジスタ)を使って文字列の比較演算などを高速に行なう命令や、iSCSIなどのエラー訂正に使われているCRCを高速に計算する「CRC32」、音声認識などパターンマッチングを高速にする「POPCNT」などといった命令が含まれる。SSEというとエンコードなどのマルチメディア処理を高速にするというイメージが強いが、今回のSSE4.2はかなり性質が異なっている。 |
||||||||||||||
|
||||||||||||||
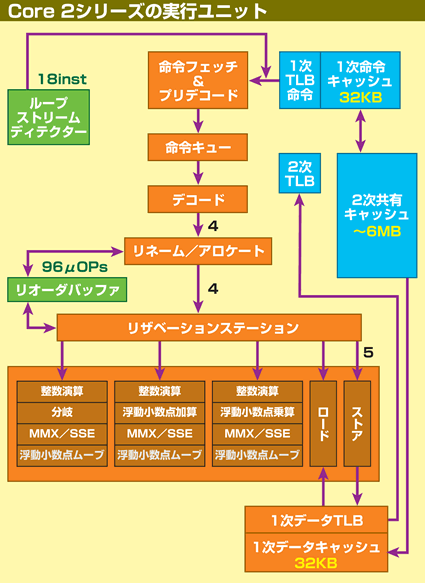 |
||||||||||||||
| Core MA(Merom)の命令とデータの流れを示すブロック図。ループ命令をキャッシュするLSDは命令フェッチの前に配置されている。図中の数字は1サイクルで処理される命令の数を示しているが、実行ユニットへの命令発行ポートは5ポートだ | ||||||||||||||
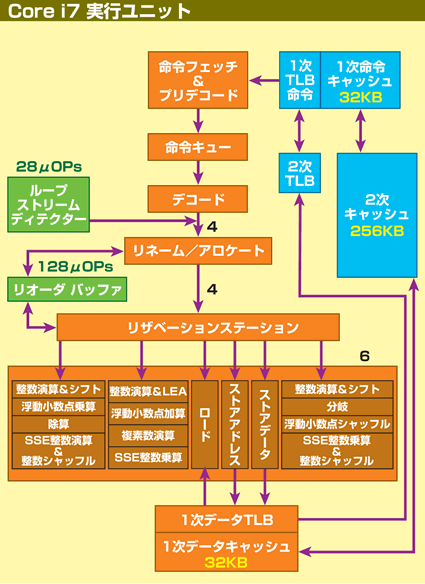 |
||||||||||||||
| Core MA(Nehalem)のブロック図。基本的な構造は大部分継承されているが、LSDはデコードの後に置かれ、μOPsで保存するよう変更された。また、ストアユニットが二つに分かれ、命令発行ポートが六つに増えている | ||||||||||||||
|
||||||||||||||
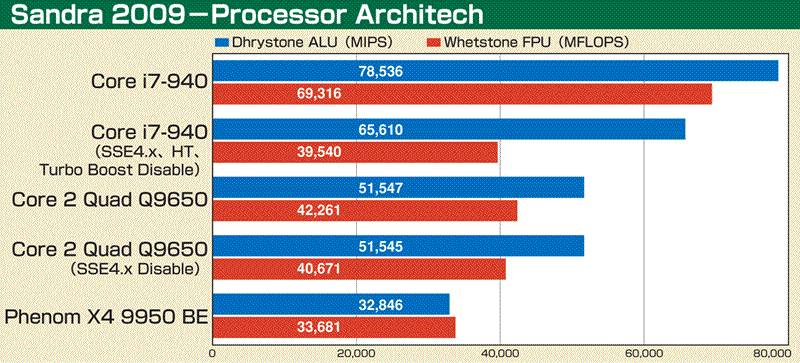
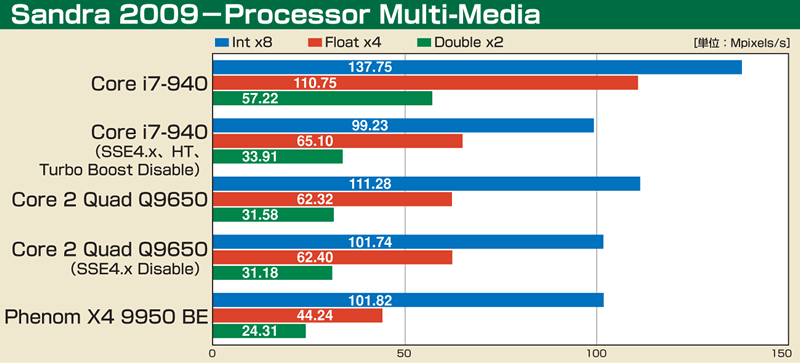
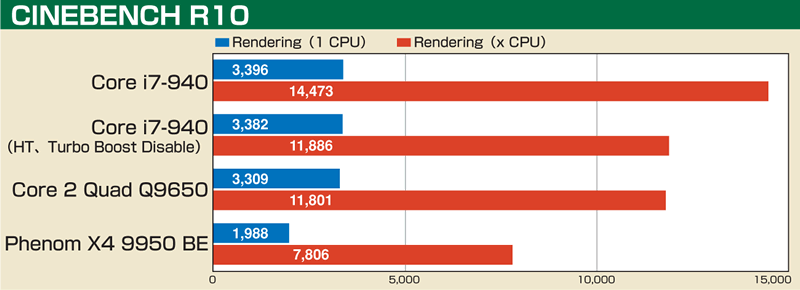
| これまで見てきたように、マイナーチェンジながらも全体的に見直しが行なわれ、少しずつリソースがリッチになっているのがCore i7のMAの特徴だ。これらの効果はどのように現われるのか、ベンチマークテストを行なった。まずはSandra 2009のProcessor Architech。このテスト(Dhrystone ALU)はSSE4.2に対応しているため、そのままでは横並びの比較にならないが、設定でSSE4.xの有効/無効が選べる。ここでSSE4.xをOFFにし、さらにBIOSでHyper-ThreadingやTurbo BoostといったCore i7の新フィーチャーをOFFにした状態で、クロックが近いCore 2 Quad Q9650(SSE4.x OFF)と比較してみた。その結果は、整数演算(ALU)では27%Core i7のほうが速かったが、浮動小数点演算(FPU)では逆に3%Core 2 Quad Q9650のほうが高速だった。Core i7のほうがクロックが低いことを考えると3%程度の差は相殺できないこともないが、少なくともHyper-ThreadingやTurbo Boostの効果を抜きにすれば、浮動小数点演算はほとんど向上していないことが分かる。逆に整数演算の向上はかなりものだ。 次はSandra 2009のProcessor Multi-Mediaのスコアを見てみよう。SSE命令を使ったマンデルブロー図形の描画性能から演算性能を見るもので、整数(Int)、単精度浮動小数点(Float)、倍精度浮動小数点(Double)と3種類を確認できる。こちらもCore i7の新フィーチャーをOFFにするとCore 2 Quad Q9650とほとんど変わらない結果になった。 実際のアプリケーションの一例としてCINEBENCH R10も試してみたが、ここでも傾向は変わらない。1コアのみを使用する1 CPU、使用可能な全コアを使うx CPU、いずれもCore i7-940のHyper-ThreadingとTurbo BoostをOFFにした状態ではCore 2 Quad Q9650に比べてごくわずかなスコアアップにとどまった。Core i7のほうが動作クロックは若干低いとはいえ、Sandraと違ってメモリまわりの改良効果も反映されていることを考えると、やはりコア改良の影響はほとんどないと言える。 もっとも、Sandraでの整数演算性能は確実に向上しているし、浮動小数点演算やSSE演算の性能も新フィーチャーを無効にした状態で差がないわけであって、有効にした場合にははっきりとした向上が見られる。つまりは、今回のコア拡張は、Core i7の新フィーチャーの効果をより発揮させるための性格が強いと考えられる。なかでもHyper-Threadingを強く意識した拡張だと言えるだろう。 |
||||||||||||||
 |
||||||||||||||
 |
||||||||||||||
 |
||||||||||||||
|
||||||||||||||
|
|
サイト内検索
DOS/V POWER REPORT 最新号
-

-
DOS/V POWER REPORT
2024年冬号発売日:12月28日
特別定価:2,310円
書籍(ムック)

-
PC自作・チューンナップ虎の巻 2023【DOS/V POWER REPORT特別編集】
発売日:2022/11/29
販売価格:1,800円+税

-
このレトロゲームを遊べ!
発売日:2019/05/29
販売価格:1,780円+税

-
特濃!あなたの知らない秋葉原オタクスポットガイド
発売日:2019/03/25
販売価格:1,380円+税

-
わがままDIY 3
発売日:2018/02/28
販売価格:980円+税

-
忍者増田のレトロゲーム忍法帖
発売日:2017/03/17
販売価格:1,680円+税

-
楽しいガジェットを作る いちばんかんたんなラズベリーパイの本
発売日:2016/09/23
販売価格:2,400円+税

-
DVDで分かる! 初めてのパソコン自作
発売日:2016/03/29
販売価格:1,480円+税

-
ちょび&姉ちゃんの『アキバでごはん食べたいな。』2
発売日:2015/12/10
販売価格:1,280円+税

-
髙橋敏也の改造バカ一台&動く改造バカ超大全 風雲編
発売日:2015/06/29
販売価格:2,500円+税

-
髙橋敏也の改造バカ一台&動く改造バカ超大全 怒濤編
発売日:2015/06/29
販売価格:2,500円+税

-
わがままDIY 2
発売日:2015/02/27
販売価格:980円+税

-
ちょび&姉ちゃんの『アキバでごはん食べたいな。』
発売日:2014/12/05
販売価格:1,280円+税
-

-
わがままDIY 1
発売日:2011/12/22
販売価格:980円+税

アンケートにお答え頂くには「CLUB IMPRESS」への登録が必要です。

*プレゼントの対象は「DOS/V POWER REPORT最新号購入者」のみとなります。
ユーザー登録から アンケートページへ進んでください
![]() Copyright © 2022 Impress Corporation. All rights reserved.
Copyright © 2022 Impress Corporation. All rights reserved.